강화학습 알아보기(5) - 문과 열쇠가 있는 문제 풀기
09 Jun 2019 • 0 Comments
지난 글에서는 Grid World 의 ball-find-3 문제를 풀기 위한 Actor-Critic, A2C, A3C 알고리즘에 대해서 알아보고 에이전트가 환경을 어떻게 해석하는지 알아보기 위해 액션 시각화를 했습니다. A3C는 하나의 에이전트 대신에 여러 개의 에이전트를 쓴다는 간단한 아이디어로 높은 퍼포먼스를 내는 알고리즘이었습니다. 이번 시간에는 지금까지 풀어왔던 ball-find-3를 벗어나 다른 문제를 푸는 데에 A3C 알고리즘을 사용해 보겠습니다.
two-room 문제
이 시리즈의 두번째 글부터 네번째 글까지 함께한 ball-find-3는 기본적으로 비어 있는 8x8 Grid에서 3개의 ball 을 에이전트가 찾아야 하는 문제였습니다. 비어 있다는 것은 에이전트의 행동을 제약하는 조건이 없다는 뜻입니다. 환경의 끝에서는 더 이상 움직일 수 없지만, 그렇지 않다면 어디로든 자유롭게 이동 가능했습니다.
이번에 제시하는 two-room 문제는 8x8 Grid를 가로 또는 세로로 뻗은 벽으로 나누고, 따라서 환경에는 두 개의 방이 생깁니다. 벽에는 빈 공간이 한 칸 포함되기 때문에 에이전트는 이 통로를 이용해서 두 방 사이를 드나들 수 있습니다. 환경에는 ball 한 개가 존재하고, 이 ball은 에이전트가 있는 방이 아닌 다른 방에 배치됩니다. 따라서 에이전트는 현재 위치한 방에서 ball이 있는 방으로 이동해서 ball을 획득할 수 있어야 합니다. ball을 획득하면 episode는 끝나고, ball의 reward는 +3, 학습을 촉진시키기 위해 global reward로 -0.1이 주어집니다.
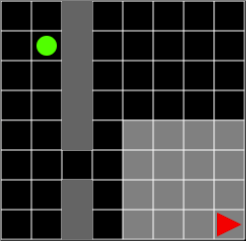 그림 1. 에이전트와 ball은 서로 다른 방에 배치됩니다. 에이전트는 가급적 벽에 적게 부딪치면서 통로를 통과하는 방법을 학습해야 합니다.
그림 1. 에이전트와 ball은 서로 다른 방에 배치됩니다. 에이전트는 가급적 벽에 적게 부딪치면서 통로를 통과하는 방법을 학습해야 합니다.
ball-find-3처럼 에이전트는 자신 주변 7x7의 제한된 공간에 대한 시야만 갖게 됩니다. 에이전트가 벽을 향해 이동하면 에이전트의 행동은 무효화됩니다. 즉 제자리에서 움직이지 않은 것과 마찬가지가 됩니다. 따라서 에이전트는 global reward인 -0.1을 최소한으로 받기 위해서 최소 시간 안에 목표인 ball을 획득해야 하고 그러기 위해 가급적 벽에 적게 부딪치면서 통로를 통과하는 방법을 학습해야 합니다.
랜덤한 행동은 특히 이러한 벽의 제약조건 안에서는 몹시 비효율적으로 동작할 것입니다. 강화학습에서 최근에 제시되는 문제들을 보면 랜덤한 행동을 하는 에이전트가 점수를 거의 내지 못하는 어려운 문제를 제시합니다.1 아타리 게임 중에서 가장 어려운 게임으로 평가되는 몬테주마의 복수(Montezuma’s Revenge)는 DQN으로 학습시켜도 점수를 내지 못할 정도로 어렵습니다.2
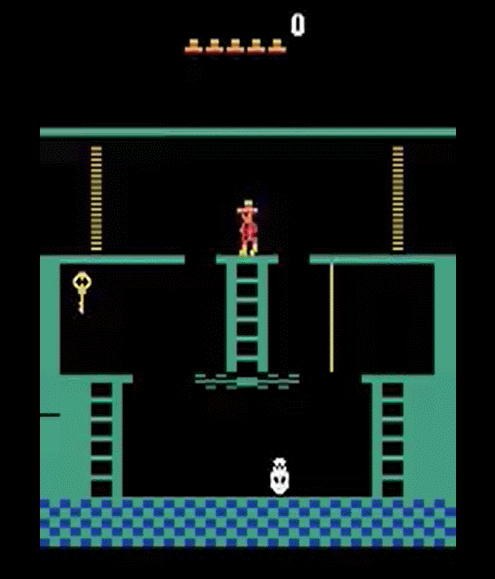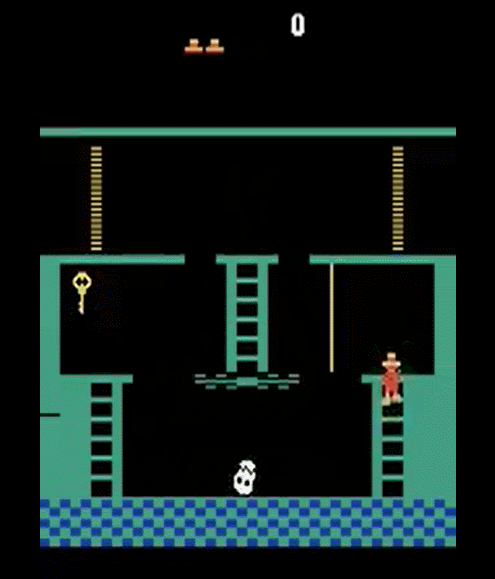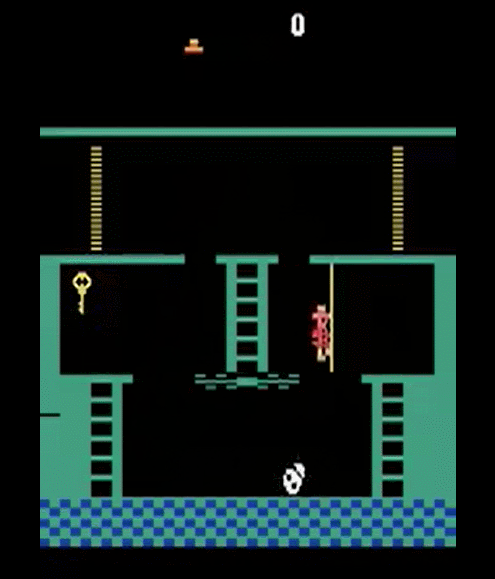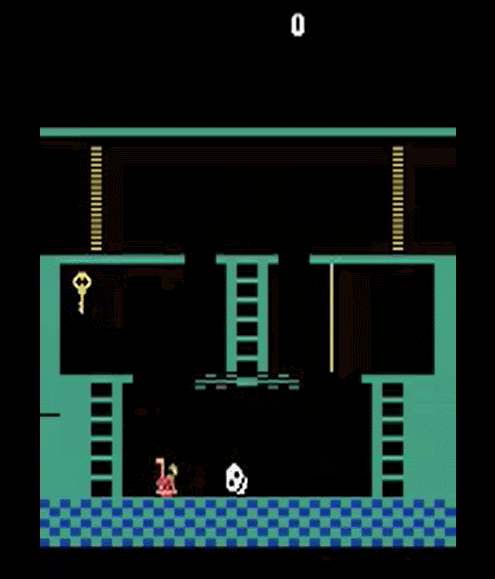 그림 2. 몬테주마의 복수 게임을 랜덤 에이전트로 플레이하려고 하면 점수를 거의 내지 못합니다. 출처 링크
그림 2. 몬테주마의 복수 게임을 랜덤 에이전트로 플레이하려고 하면 점수를 거의 내지 못합니다. 출처 링크
여기서는 ball-find-3에서 좋은 성과를 보였던 A2C 알고리즘을 사용해서 에이전트를 학습시켜보겠습니다.
Learn(A2C) 버튼을 눌러서 에이전트를 학습시킵니다. 2,000 episode까지 진행하면 avg. reward는 -8~-12 정도가 나옵니다. 좀 더 진행하면 -2~-4 정도로 높은 reward를 얻게 됩니다.
또 maxStep인 200에 도달하기 전에 episode가 완료된 비율을 알아보기 위해서 ball을 얻은 횟수와 전체 시도에 대한 성공률을 표시했습니다. 처음에는 거의 완료하지 못하다가 2,000 episode까지 진행하면 약 40~50%, 10,000 episode까지 진행하면 약 70% 이상의 성공률을 보입니다.
이제 이 시리즈를 계속 읽어오신 분들은 같은 환경에서 A3C를 실행하면 A2C보다 퍼포먼스가 나아질 것이라고 예상하실 것입니다. 아래에 A2C와 A3C의 실험 결과를 첨부했습니다.
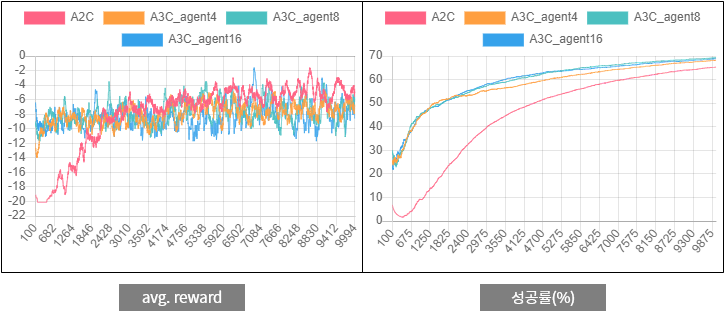 그림 3.
그림 3. two-room 문제에 대한 A2C와 A3C의 퍼포먼스 비교
에이전트가 불확실한 정보를 바탕으로 학습하기 때문에 왼쪽의 avg. reward 그래프에서는 변동폭이 큽니다. avg. reward에서는 A2C와 A3C의 차이가 크지 않은 것 같지만 오른쪽의 성공률3을 보면 A3C의 성공률이 좀 더 높습니다.
A3C 의 two-room 액션 시각화
two-room 문제에서 에이전트가 환경을 어떻게 해석하는지 알아보기 위해 액션 시각화를 해볼 수 있습니다. 로컬 환경에서 16개의 에이전트를 사용한 A3C 알고리즘을 50,000 episode 동안 학습시켰습니다.
이 네트워크는 50,000 episode 까지 진행했을 때 누적 성공률 79.1%에 도달했었습니다. Load Model(A3C) 버튼을 눌러서 네트워크의 가중치를 불러오고, RUN(A3C) 버튼을 눌러서 에이전트를 움직여볼 수 있습니다. 2,000 번의 episode를 실행했을 때의 성공률은 80~85% 정도가 나옵니다.
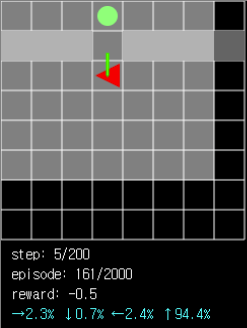 그림 4. 통로를 통과해서 다른 방에 있는 ball을 획득해야 할 때 에이전트가 통로 방향 이동을 선택할 확률은 94.4%로 매우 높게 나타납니다.
그림 4. 통로를 통과해서 다른 방에 있는 ball을 획득해야 할 때 에이전트가 통로 방향 이동을 선택할 확률은 94.4%로 매우 높게 나타납니다.
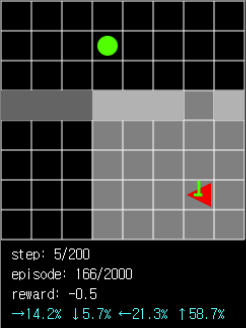 그림 5. 에이전트의 시야에 ball이 없어도 벽이 시야에 들어오면 통로를 통과하는 쪽으로 이동할 확률이 높은 것을 확인할 수 있습니다.
그림 5. 에이전트의 시야에 ball이 없어도 벽이 시야에 들어오면 통로를 통과하는 쪽으로 이동할 확률이 높은 것을 확인할 수 있습니다.
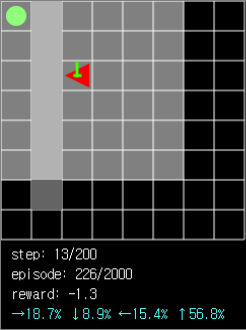 그림 6. 에이전트의 시야가 제한된 상태에서 통로가 ball과는 반대방향에 있는 경우 ball과 가까워지려는 경향 때문에 탐색에 실패할 수도 있습니다.
그림 6. 에이전트의 시야가 제한된 상태에서 통로가 ball과는 반대방향에 있는 경우 ball과 가까워지려는 경향 때문에 탐색에 실패할 수도 있습니다.
에이전트는 80% 이상의 경우 성공하지만 통로와 ball이 너무 멀거나 반대방향에 있는 경우에 실패하는 모습도 보입니다. 이 부분은 지난 시간에도 언급한 것처럼 에이전트에 과거 정보를 기억할 수 있는 메모리를 추가하면 개선될 것 같습니다.
two-room-door-key 문제
위에서 풀었던 two-room 문제에 약간 더 어려운 조건을 추가한 two-room-door-key 문제를 생각해볼 수 있습니다.
two-room-door-key 문제에서 두 개의 방은 빈 공간 대신 굳게 닫힌 문으로 연결되어 있고, 이 문은 열쇠로만 열리고, 열쇠는 에이전트와 같은 방 안에 있습니다. 열쇠를 얻을 때 reward +1, 열쇠로 문을 열 때 reward +1, ball을 획득할 때 reward +1을 얻습니다. 목표가 되는 ball이 에이전트와 다른 방에 있다는 조건과 global reward로 주어진 -0.1 등은 동일합니다.
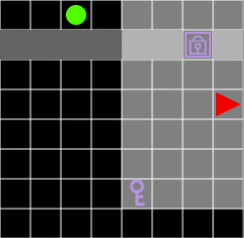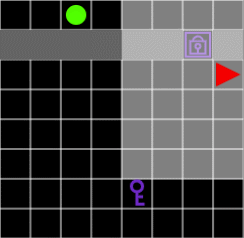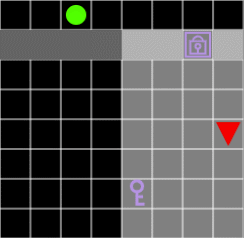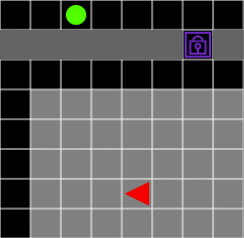 그림 7. 열쇠가 없으면 에이전트는 문을 통과할 수 없습니다.
그림 7. 열쇠가 없으면 에이전트는 문을 통과할 수 없습니다.
에이전트가 가장 먼저 해야할 일은 열쇠를 찾는 일입니다. 그 다음 문으로 이동해야 하며, 문을 열고 다른 방으로 이동하고, ball을 찾아서 획득해야 episode 가 성공적으로 끝납니다. 한번에 두 개의 조건이 추가되었기 때문에 문제의 난이도가 올라갈 것으로 예상됩니다. 이번에도 A2C로 퍼포먼스를 테스트해보겠습니다.
역시 Learn(A2C) 버튼을 눌러서 에이전트를 학습시킬 수 있습니다. 그런데 two-room에 비해 어려워진 문제라고 생각했지만 2,000 episode까지 학습시켜보면 ball을 획득하는 확률이 오히려 더 높아진 것을 확인할 수 있습니다.
이는 이 문제의 에이전트가 기본적으로 불확실한 정보를 바탕으로 결정을 내려야 하는 상황 속에서 판단을 내릴 수 있는 단서의 수가 더 많아졌기 때문인 것으로 생각됩니다. 벽과 빈 공간만 있는 것보다 door가 있으면 door로 이동해야 한다는 행동을 reward를 통해 학습하는 것이 결과적으로 반대편 방에 있는 ball을 획득하는 데에 도움이 되는 것 같습니다.
여기서도 역시 A3C 알고리즘을 써서 A2C와 퍼포먼스를 비교해보도록 하겠습니다.
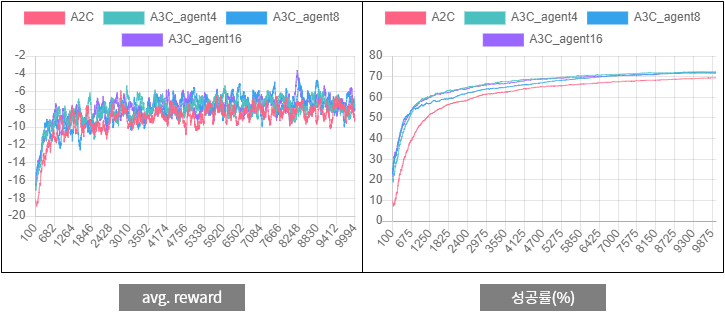 그림 8.
그림 8. two-room-door-key 문제에 대한 A2C와 A3C의 퍼포먼스 비교
two-room 문제에 비해 A2C보다는 A3C의 avg. reward와 성공률이 좋게 나옵니다. 10,000 episode정도 진행하면 A3C 알고리즘은 성공률 70%를 넘게 됩니다. 로컬에서 실험해본 결과 50,000 episode까지 학습시킬 때도 꾸준히 성공률이 오르는 것을 확인할 수 있었습니다.
A3C 의 two-room-door-key 액션 시각화
two-room-door-key 문제에서 에이전트가 환경을 어떻게 해석하는지 알아보기 위해 액션 시각화를 해볼 수 있습니다. 로컬 환경에서 16개의 에이전트를 사용한 A3C 알고리즘을 36,500 episode 동안 학습시켰습니다.
이 네트워크는 36,500 episode까지 진행했을 때 누적성공률 73%에 도달했습니다. door를 통과한 확률은 88.7%, key를 획득한 확률은 94.2%였습니다.
학습된 에이전트는 key 획득 → door 통과 → ball 획득 순서대로 episode를 잘 완료하지만 그림 10처럼 key를 아직 획득하지 못한 상황에서 무조건 door쪽을 향하는 경향이 있는 것을 확인할 수 있습니다. 이는 에이전트의 key 획득 여부를 메모리나 input에 저장하지 않기 때문입니다. Input에 agent의 상태 중 key 획득 여부를 추가하거나 메모리에 이전 step의 정보를 저장한다면 개선될 것으로 생각됩니다.
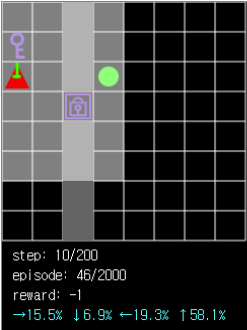 그림 9. 에이전트는 key와 가까운 거리에 있을 경우 key를 먼저 획득하려는 경향성을 가집니다.
그림 9. 에이전트는 key와 가까운 거리에 있을 경우 key를 먼저 획득하려는 경향성을 가집니다.
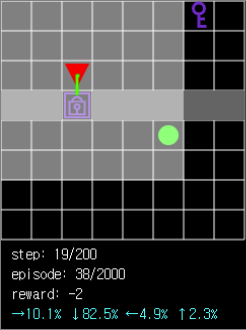 그림 10. key 획득 여부를 메모리나 input에 저장하지 않기 때문에 key 없이도 door쪽으로 향하는 오류가 발생합니다.
그림 10. key 획득 여부를 메모리나 input에 저장하지 않기 때문에 key 없이도 door쪽으로 향하는 오류가 발생합니다.
커리큘럼 러닝
커리큘럼 러닝은 2018 튜링상을 공동으로 수상한 Yoshua Bengio 교수 등이 2009년에 발표한 논문에 나오는 개념으로, 학습에 필요한 샘플을 난이도 순서대로 쉬운 것을 먼저, 어려운 것을 나중에 제시할 때 학습 효율이 올라간다는 주장입니다. 도형 형태 인식과 언어 모델링 등의 실험 결과에서 이 학습법은 일반화될 수 있는 가능성을 보여줬습니다.
최근 딥러닝과 강화학습이 주목받으면서 일반적인 학습 방법을 개선시키는 커리큘럼 러닝도 같이 주목받고 있습니다. 일반적인 방법이기 때문에 지금까지 살펴본 Grid World 에도 커리큘럼 러닝을 사용할 수 있습니다.
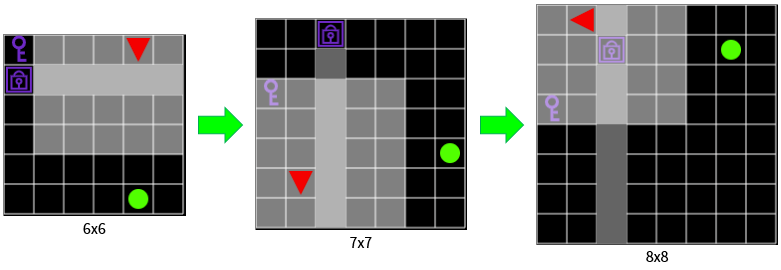 그림 11. 네트워크가 준비되지 않은 상태에서 어려운 문제를 많이 만나지 않도록 쉬운 문제를 먼저 제시해줍니다.
그림 11. 네트워크가 준비되지 않은 상태에서 어려운 문제를 많이 만나지 않도록 쉬운 문제를 먼저 제시해줍니다.
에이전트가 풀 문제는 two-room-door-key이며, 학습 환경은 6x6부터 기존의 8x8 Grid까지 랜덤하게 제시되고 학습의 후반부로 갈수록 큰 환경이 더 많이 제시됩니다. 큰 환경일수록 에이전트가 한번에 볼 수 있는 영역이 넓어지기 때문에 풀기 어려운 문제가 됩니다.
A3C의 온라인 학습은 오래 걸리기 때문에 여기서는 A2C로 학습을 해보겠습니다. 각 학습 단계에서 제시되는 환경의 비율은 그림 12에 표시되어 있습니다.
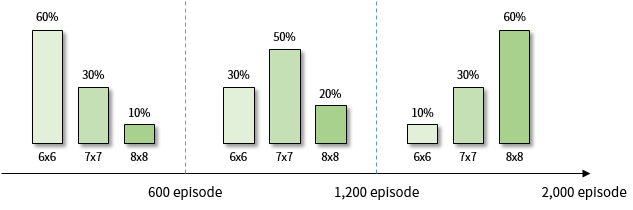 그림 12. A2C 학습 단계에서 제시되는 환경의 비율
그림 12. A2C 학습 단계에서 제시되는 환경의 비율
2,000 episode까지 학습시켰을 때 8x8 Grid의 성공률은 65~68% 정도가 나옵니다. 위에서 커리큘럼 러닝을 적용하지 않은 A2C의 성공률이 40~50% 정도 나왔던 것과 비교하면 크게 개선되었습니다.
더 좋은 결과를 얻기 위해 4개의 에이전트를 이용한 A3C를 10,000 episode 동안 학습시켜 보았습니다. 각 학습 단계에서 환경이 출현하는 비율은 그림 13에 표시되어 있습니다. 그림 12과 같은 비율이고 총 episode 만 10,000 으로 늘렸습니다.
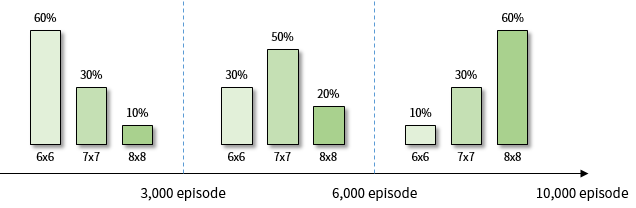 그림 13. A3C(4 agents) 학습 단계에서 제시되는 환경의 비율
그림 13. A3C(4 agents) 학습 단계에서 제시되는 환경의 비율
커리큘럼 러닝 과정에서 각 환경 - 6x6, 7x7, 8x8 Grid - 에 대한 성공률이 동시에 증가하는 것을 확인할 수 있습니다.
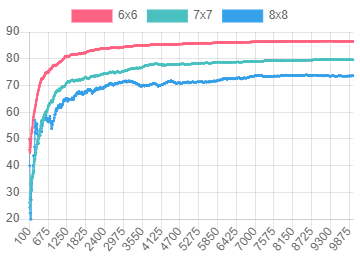 그림 14.
그림 14. two-room-door-key 문제에서 A3C(4 agents) 알고리즘으로 에피소드를 진행할 때 각 환경에서의 성공률
학습 과정에서 커리큘럼 러닝은 더 빠른 속도로 더 높은 성공률을 달성했습니다. 같은 episode 에서 커리큘럼 러닝을 사용한 A3C는 8x8 Grid 의 문제를 풀 때 일반 A3C보다 2~5% 정도 성공률이 더 높았습니다.
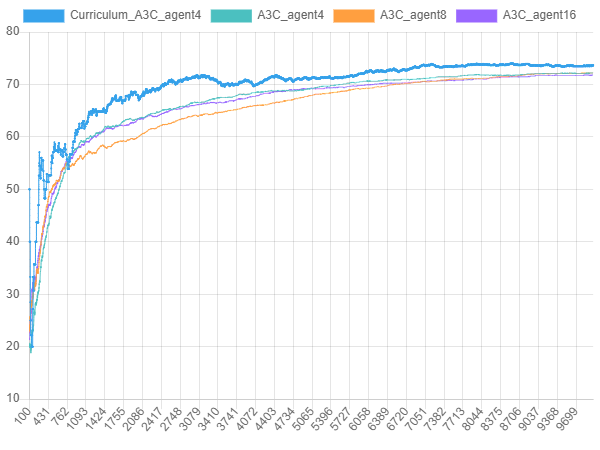 그림 15.
그림 15. two-room-door-key 문제에서 커리큘럼 러닝을 사용한 A3C(4 agents)와 일반 A3C(4, 8, 16 agents)의 성공률 비교
이것으로 5회에 걸친 “강화학습 알아보기” 시리즈의 연재를 마무리하려고 합니다. 이 시리즈로 강화학습에 대한 모든 내용을 알아본 것은 아니지만, 강화학습에 대해 한번쯤 경험해보고 싶은 분들께 복잡한 프로그램 설치 없이 interactive 한 웹 환경에서 강화학습 과정과 에이전트의 행동을 관찰할 수 있게 제공해드릴 수 있었다는 점에 의의를 두고 싶습니다. 다음에 기회가 된다면 좀 더 흥미로운 주제를 들고 돌아오고 싶습니다. 긴 글을 끝까지 읽어주셔서 감사합니다.
-
CoG 2019의 Competition 종목 중 하나인 Bot Bowl I은 미식 축구를 턴제 게임으로 해석한 워해머 프랜차이즈의 게임 Blood Bowl을 기반으로 하고 있습니다. 랜덤 행동 에이전트로 350,000게임을 진행했지만 1점도 내지 못할 만큼 어려운 문제입니다. 논문 링크 ↩
-
Deepmind 와 OpenAI 는 2018년에 몬테주마의 복수 게임을 풀 수 있는 새로운 방법을 여러 개(Single Demonstration, RND, watching Youtube) 발표했습니다. ↩
-
maxStep 을 넘기 전에 ball을 획득한 episode 수 / 전체 episode 수 * 100 ↩