Learn Reinforcement Learning (5) - Solving problems with a door and a key
09 Jun 2019 • 0 Comments
two-roomproblem- A3C’s
two-roomaction visualization two-room-door-keyproblem- A3C’s
two-room-door-keyaction visualization - Curriculum Learning
In the previous article, we looked at the Actor-Critic, A2C, and A3C algorithms for solving the ball-find-3 problem in Grid World and did an action visualization to see how the agent interpreted the environment. A3C was a high-performance algorithm with a simple idea of using multiple agents instead of a single agent. This time, let’s try the A3C algorithm to solve other problems out of ball-find-3 that we have been solving so far.
two-room problem
The ball-find-3 problem from the second to the fourth article in this series was basically an issue where agents had to find three balls in an empty 8x8 Grid. Empty means that there are no constraints on agent behavior. At the end of the environment it can no longer move, but if it is not, it can move freely anywhere.
This two-room problem divides the 8x8 Grid into horizontally or vertically extending walls, so there are two rooms in the environment. Because the wall contains one space, the agent can use this passage to move between the two rooms. There is one ball in the environment, and this ball is placed in a room other than the room with the agent. Therefore, the agent must be able to move to the room where the ball is located in order to acquire the ball. If the ball is acquired, the episode ends, the ball’s reward is +3, and the global reward is -0.1 to facilitate learning.
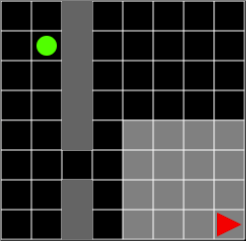 Figure 1. Agent and ball are placed in different rooms. The agent should learn how to pass through the aisle as little as possible against the wall.
Figure 1. Agent and ball are placed in different rooms. The agent should learn how to pass through the aisle as little as possible against the wall.
Like ball-find-3, the agent only has visibility for a limited space of 7x7 around itself. When the agent moves toward the wall, the agent’s behavior is invalidated. It is the same as if it did not move in place. Therefore, the agent must acquire the target ball within the minimum time to get the global reward of -0.1 to the minimum, and it is necessary to learn how to pass through the passage as little as possible against the wall.
Random actions will be very inefficient especially within these wall constraints. Recent challenges in Reinforcement Learning present a difficult problem where agents with random actions rarely score.1 Montezuma’s Revenge, rated as the hardest game in the Atari game, is difficult to score even with a DQN.2
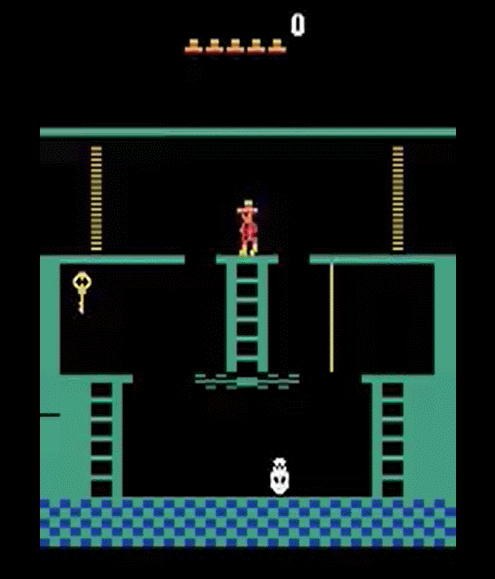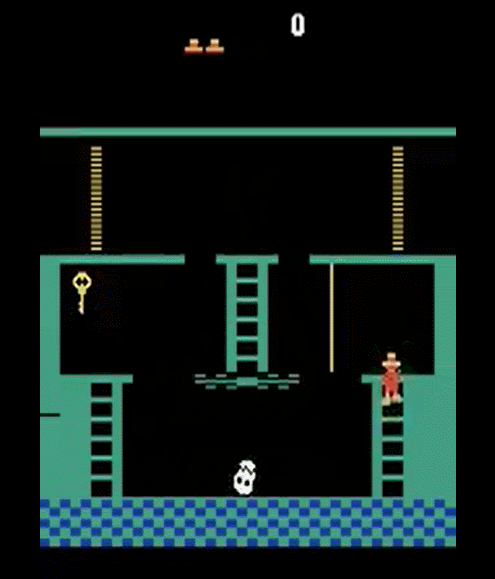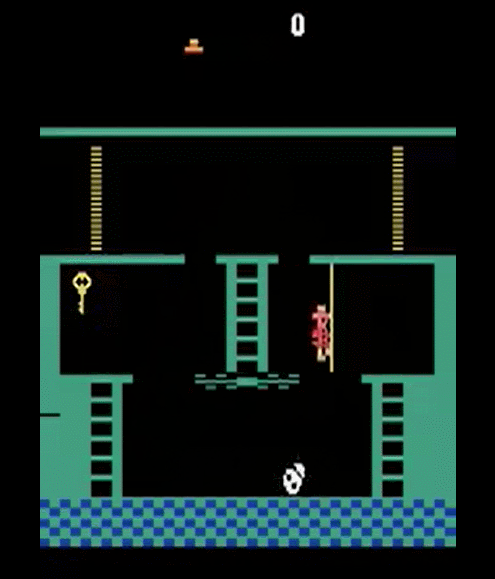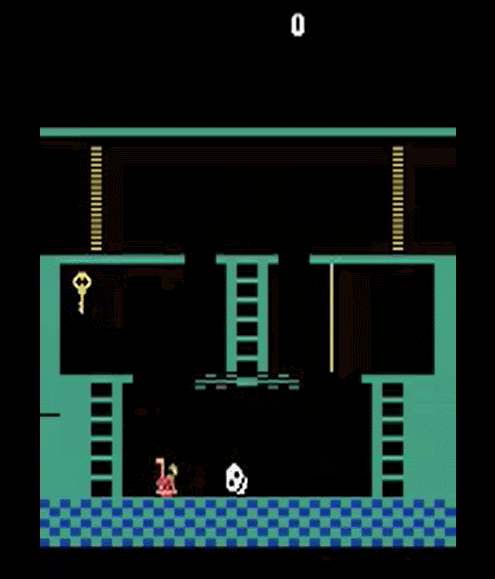 Figure 2. If you try to play Montezuma’s multiplayer game as a random agent, you will not get enough points. Source Link
Figure 2. If you try to play Montezuma’s multiplayer game as a random agent, you will not get enough points. Source Link
Here we will use the A2C algorithm, which has performed well in ball-find-3, to learn the agent.
Press the Learn (A2C) button to learn the agent. If you go up to 2,000 episodes, the average reward is around -8 to -12. If you go further, you get a high reward of -2 to -4.
I also showed how many episodes were completed before reaching the maxStep of 200, the number of times the ball was acquired, and the success rate for all trials. At the beginning, it is almost impossible to complete, but if you go up to 2,000 episodes, you’ll get about 40-50%. If you go up to 10,000 episodes, you’ll see a success rate of about 70%.
Now, if you continue reading this series, you expect that performance will be better than A2C if you run A3C in the same environment. Attached below are the results of A2C and A3C.
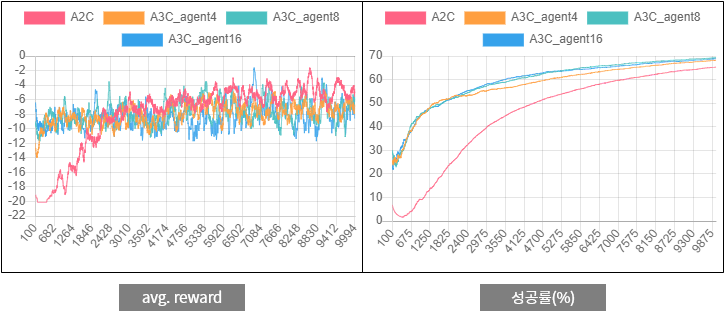 Figure 3. Comparison of A2C and A3C performance for
Figure 3. Comparison of A2C and A3C performance for two-room problems
Since the agent learns based on uncertain information, the average reward graph on the left has a large fluctuation. In the average reward, the difference between A2C and A3C is not big, but the success rate3 on the right side is higher than that of A3C.
A3C’s two-room action visualization
In a two-room problem, we can try to visualize the action to see how the agent interprets the environment. The A3C algorithm using 16 agents in the local environment was learned for 50,000 episodes.
The network had a cumulative success rate of 79.1% when running up to 50,000 episodes. Press the Load Model (A3C) button to load the network weights, and press the RUN (A3C) button to move the agent. When you run 2,000 episodes, the success rate is 80% to 85%.
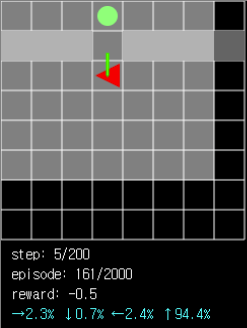 Figure 4. The probability that the agent chooses to move the pathway is very high (94.4%) when it is necessary to acquire the ball in another room through the passage.
Figure 4. The probability that the agent chooses to move the pathway is very high (94.4%) when it is necessary to acquire the ball in another room through the passage.
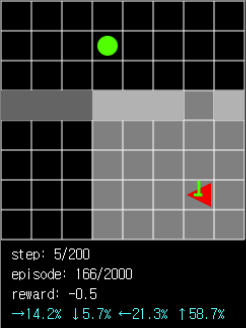 Figure 5. Even if there is no ball in the agent’s field of view, it can be seen that when the wall enters the field of view, there is a high probability of moving to pass through the passage.
Figure 5. Even if there is no ball in the agent’s field of view, it can be seen that when the wall enters the field of view, there is a high probability of moving to pass through the passage.
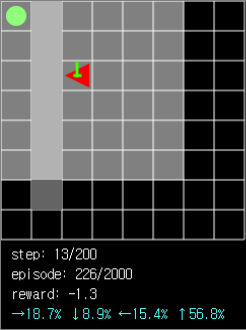 Figure 6. If the path is in the opposite direction to the ball while the agent’s field of view is limited, the search may fail due to the tendency to approach the ball.
Figure 6. If the path is in the opposite direction to the ball while the agent’s field of view is limited, the search may fail due to the tendency to approach the ball.
Agents will succeed if they are over 80%, but they will also fail if the path and ball are too far away or in the opposite direction. As I mentioned last time, this section will be improved by adding memory to the agent to remember past information.
two-room-door-key problem
Think about the two-room-door-key problem that added slightly more difficult conditions to the two-room problem that was solved above.
In the two-room-door-key problem, two rooms are connected by a firmly closed door instead of an empty space, the door is only opened by a key, and the key is in the same room as the agent. When agent get the key, agent get reward +1, when agent open the door with the key, agent get reward +1, when agent get the ball, agent get reward +1. The condition that the target ball is in a different room from the agent and -0.1 given by the global reward are the same.
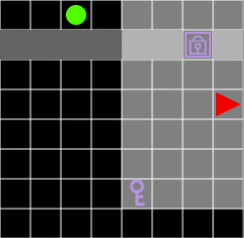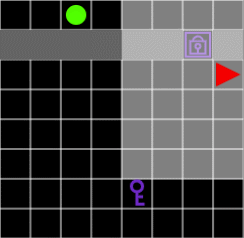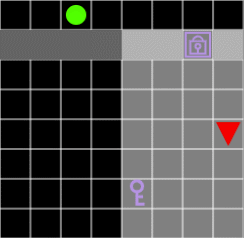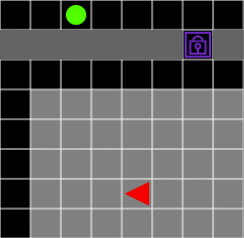 Figure 7. Without the key, the agent can not pass through the door.
Figure 7. Without the key, the agent can not pass through the door.
The first thing an agent needs to do is find a key. You must move to the next door, open the door, move to the other room, find the ball and acquire it, the episode ends successfully. Because two conditions are added at once, the difficulty level of the problem is expected to increase. Again, let’s test the performance with A2C.
You can also learn the agent by pressing the Learn (A2C) button. However, I thought it was a difficult problem compared to the two-room, but if you study up to 2,000 episodes, you can see that the probability of acquiring a ball is higher.
This is probably due to the fact that the agents in this issue have more clues to make judgments in the context of basing decisions based on uncertain information. Learning to reward the action of having to go to the door if there is a door rather than just having a wall and empty space seems to help agent win the ball in the other room as a result.
Here again, let’s compare the A2C with the performance using the A3C algorithm.
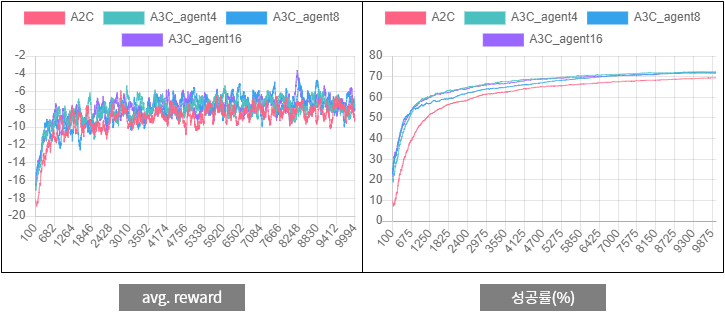 Figure 8. Comparison of A2C and A3C performance for
Figure 8. Comparison of A2C and A3C performance for two-room-door-key problem
Compared to the two-room problem, A3C’s average reward and success rate are better than A2C. With 10,000 episodes, the A3C algorithm will exceed 70% success rate. I have experimented locally and found that the success rate is steadily rising even when learning up to 50,000 episodes.
A3C’s two-room-door-key action visualization
You can do action visualization to see how the agent interprets the environment in a two-room-door-key problem. In the local environment, the A3C algorithm using 16 agents was learned for 36,500 episodes.
The network reached a cumulative success rate of 73% when running up to 36,500 episodes. The probability of passing the door was 88.7%, and the probability of obtaining the key was 94.2%.
The learned agent successfully completes the episode in the order of key acquisition → door traversal → ball acquisition, but in the situation where the key has not yet been acquired as shown in Figure 10, it can be confirmed that the agent tends to point toward the door unconditionally. This is because the agent does not store the key acquisition into memory or input. It is expected to be improved if you add key acquisition status of the agent to the input or store the information of the previous step in memory.
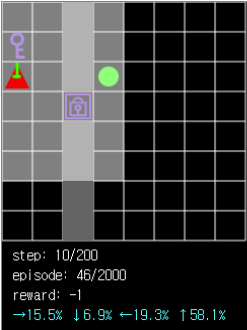 Figure 9. The agent has a tendency to acquire the key first if it is close to the key.
Figure 9. The agent has a tendency to acquire the key first if it is close to the key.
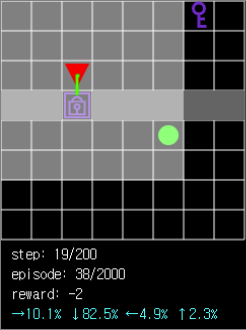 Figure 10. Since key acquisition is not stored in memory or input, an error is generated to the door without key.
Figure 10. Since key acquisition is not stored in memory or input, an error is generated to the door without key.
Curriculum Learning
Curriculum Learning is based on a paper published in 2009 by Professor Yoshua Bengio and co-recipient of the 2018 Turing Prize. It is argued that the efficiency of learning increases when the samples necessary for learning are presented in order of difficulty. Experimental results such as geometric shape recognition and language modeling have shown that this method of learning can be generalized.
Recently, deep learning and reinforcement learning have attracted attention, and curriculum learning, which improves general learning methods, is attracting attention as well. Curriculum learning is also available for Grid World, which is a common practice.
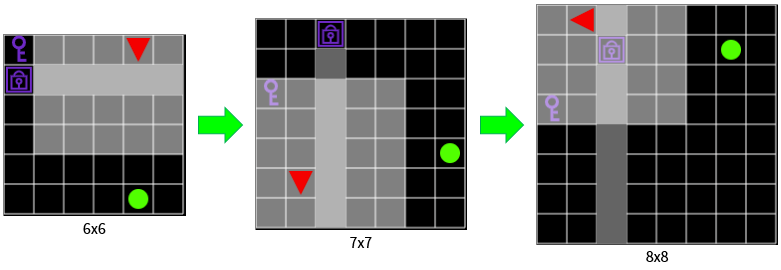 Figure 11. It presents easy problems first so that agent do not get to see a lot of difficult problems when your network is not ready.
Figure 11. It presents easy problems first so that agent do not get to see a lot of difficult problems when your network is not ready.
The agent has to solve two-room-door-key, and the learning environment is randomly presented from 6x6 to the existing 8x8 grid. As learning progresses, larger environments are presented frequently. The larger the environment, the smaller the area the agent can see at one time than the entire environment, which makes the agent difficult to unravel.
Since A3C’s online learning takes a long time, I will try learning with A2C here. The percentage of environments presented at each learning stage is shown in Figure 12.
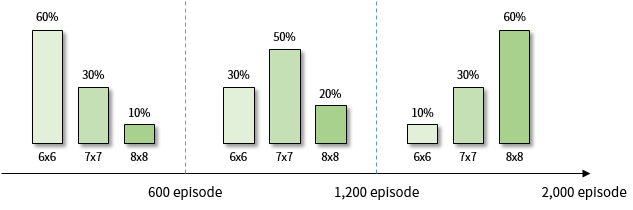 Figure 12. A2C Percentage of environment presented in the learning phase
Figure 12. A2C Percentage of environment presented in the learning phase
When learning up to 2,000 episodes, the success rate of 8x8 Grid is about 65 ~ 68%. The success rate of A2C without curriculum learning is 40 ~ 50%, so this is an improvement.
In order to get better results, I ran A3C with 4 agents for 10,000 episodes. The rate at which the environment emerges at each learning stage is shown in Figure 13. As in Figure 12, but I increased the total episode to 10,000.
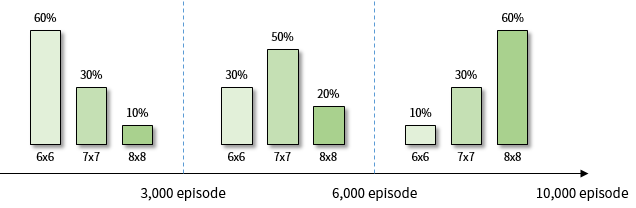 Figure 13. A3C (4 agents) Percentage of environment presented in the learning phase
Figure 13. A3C (4 agents) Percentage of environment presented in the learning phase
In the curriculum learning process, the success rate for each environment - 6x6, 7x7, 8x8 Grid - increases at the same time.
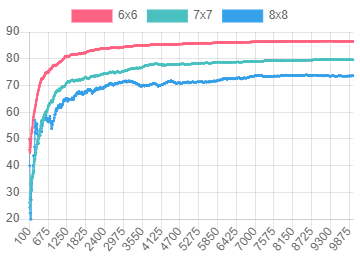 Figure 14. In the
Figure 14. In the two-room-door-key problem, when the episode is performed with the A3C (4 agents) algorithm, the success rate
Curriculum learning in the learning process achieved a higher success rate at a faster rate. A3C using curriculum learning in the same episode had a 2 to 5% more success rate when solving 8x8 Grid problems compared to regular A3C.
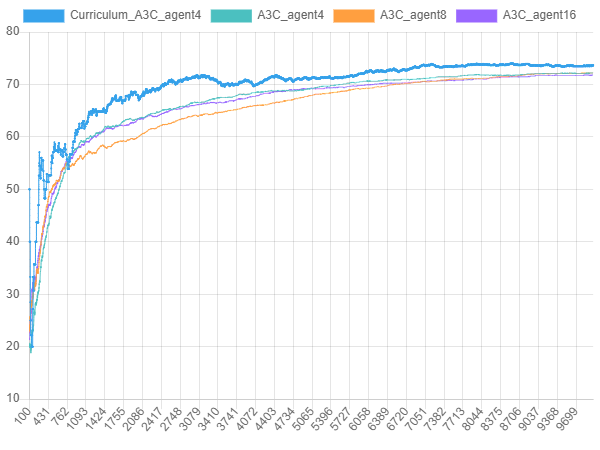 Figure 15. Comparison of the success rates of A3C (4 agents) and general A3C (4, 8, 16 agents) using curriculum learning in
Figure 15. Comparison of the success rates of A3C (4 agents) and general A3C (4, 8, 16 agents) using curriculum learning in two-room-door-key problem
With this, I intend to conclude a series of five “Learn Reinforcement Learning” series. Although this series did not cover all the details of reinforcement learning, I was able to give those who would like to experience reinforcement learning once and for all to be able to observe reinforcement learning process and agent behavior in an interactive web environment without installing complex programs. I want to make a point. If I have a chance, I’d like to come back with a more interesting topic. Thank you for reading the long article.
-
One of the CoG 2019 competitions, Bot Bowl I, is based on the Warhammer franchise’s Blood Bowl, an interpretation of football as a turn-based game. They’ve played 350,000 games with a random action agent, but it’s a tough one to score. Paper Link ↩
-
Deepmind and OpenAI announced several new ways to unlock Montezuma’s multiplayer game in 2018 (Single Demonstration, RND, watching Youtube). ↩
-
(Number of episodes that acquired the ball before passing maxStep) / (total number of episodes) * 100 ↩